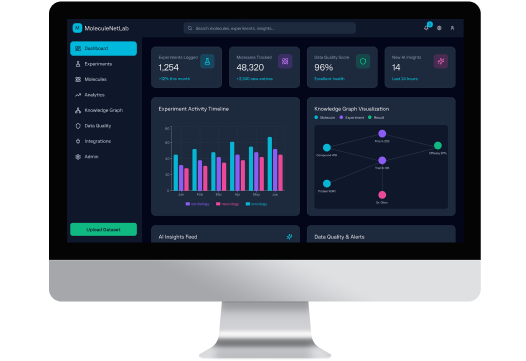
Our client, a Switzerland-based pharmaceutical company, needed to unlock strategic value from more than 10 years of fragmented laboratory and experimental data stored across PDFs, spreadsheets, and text records. With our help, the client transformed disconnected historical data into a unified AI-powered R&D platform. The solution enabled automated data extraction, terminology standardization, and knowledge graph–driven analytics, greatly enhancing data accessibility, minimizing redundant experiments, and speeding up research decision-making.
The client is a pharmaceutical company headquartered in Switzerland, operating in a research-intensive environment where laboratory experiments, molecular reactions, and compound data are generated continuously across multiple R&D initiatives.
Over the years, the company accumulated a large volume of historical research data spanning more than a decade. However, the data existed in siloed formats and lacked unified structure and terminology, limiting its reuse across projects and reducing the overall efficiency of R&D workflows.
The client faced growing limitations in accessing, analyzing, and reusing historical laboratory and experimental data across R&D initiatives. More than a decade of research data was stored in fragmented formats, including PDFs, spreadsheets, and text notes, with no unified structure or shared terminology.
As a result, scientists spent significant time manually searching for and validating past experiments, while duplicate testing increased costs and slowed discovery cycles. The lack of semantic connections between experiments, reaction conditions, and outcomes also limited the company’s ability to extract deeper insights or apply predictive analytics to research planning.
Without a scalable way to standardize, connect, and analyze historical data, the client risked underutilizing valuable research assets and missing opportunities to accelerate innovation.
Computools designed and delivered MoleculeNetLab, an AI-powered pharma R&D data platform that consolidates historical laboratory data into a single, intelligent research environment.
The solution combines automated data extraction using NLP, semantic modeling, and a knowledge graph to unify terminology, connect experiments, and reveal hidden relationships across datasets. On top of this foundation, analytics dashboards provide researchers and decision-makers with clear visibility into historical and ongoing research.
By turning disconnected records into a structured, insight-ready ecosystem, MoleculeNetLab enabled faster hypothesis validation, reduced redundant experimentation, and supported data-driven decision-making across R&D workflows.
The MoleculeNetLab platform delivered measurable improvements across the client’s R&D operations:
These results allowed scientists to verify new hypotheses more quickly, cut down on unnecessary testing, and base research decisions on interconnected historical data instead of isolated records.
Computools was selected as a technology partner due to its hands-on experience in healthcare and pharmaceutical software development, as well as its ability to work with complex, unstructured research data at scale.
The team brought together expertise in AI, NLP, vector databases, and Retrieval-Augmented Generation, along with knowledge graph architectures, to help the client organize historical data and turn it into a strategic R&D asset. A strong focus on measurable outcomes ensured that every technical decision directly supported research efficiency and data-driven decision-making.
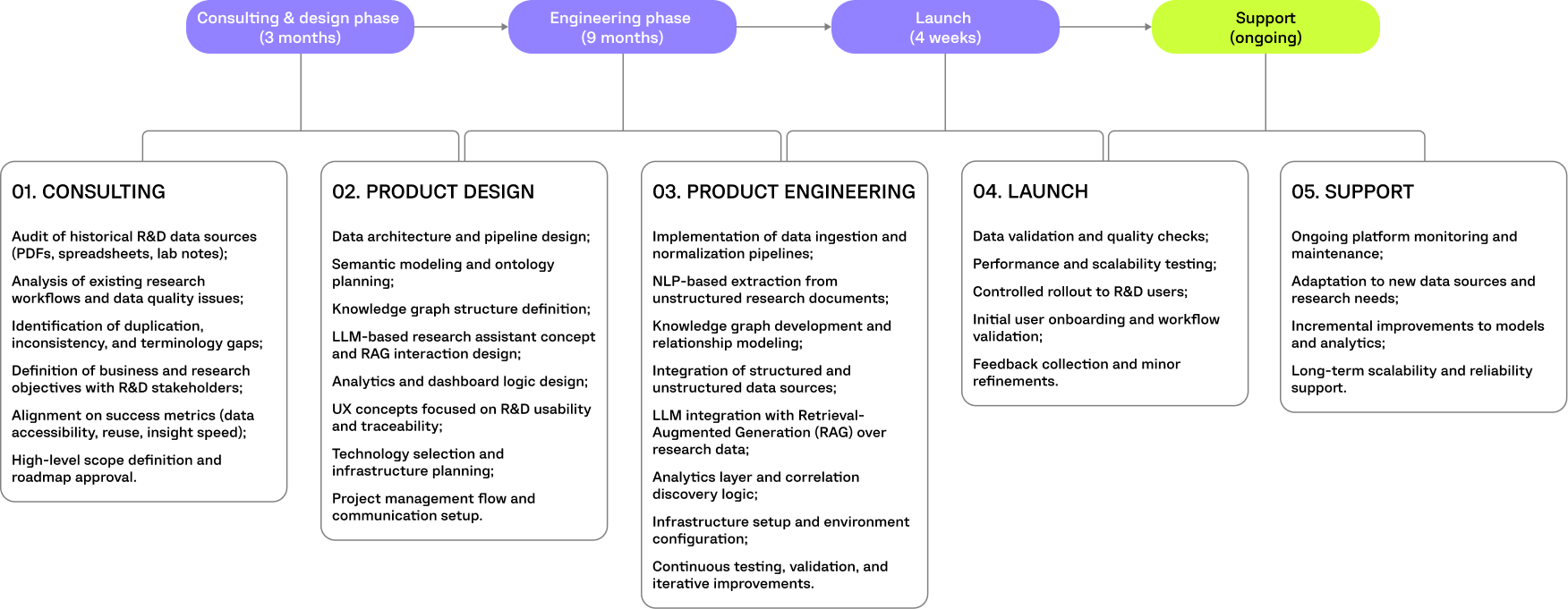
The platform design focused on making complex research data accessible and usable for scientists and decision-makers without disrupting existing R&D workflows. The goal was to translate highly technical, interconnected datasets into clear visual structures that support exploration, analysis, and informed decision-making.
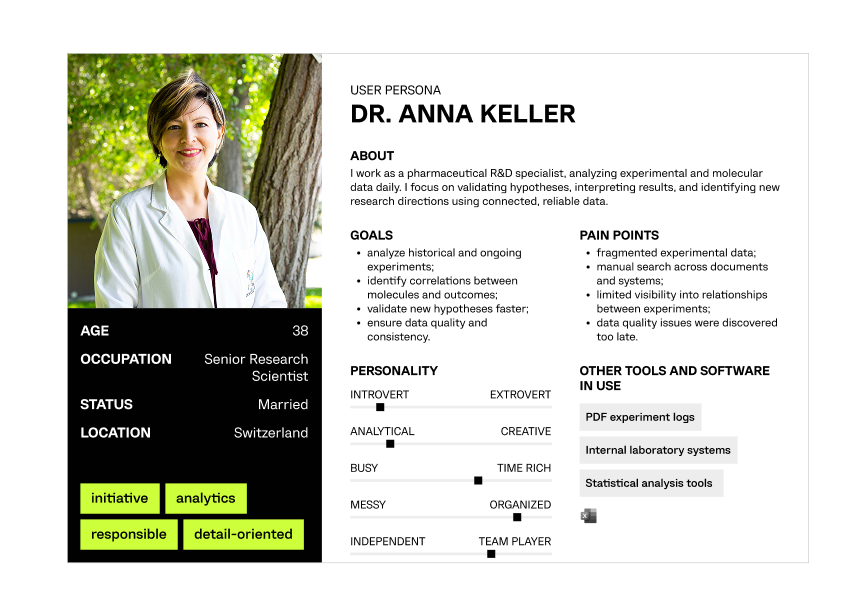
Defining key R&D users and their goals to ensure the platform supports real scientific workflows, data exploration, and decision-making needs.
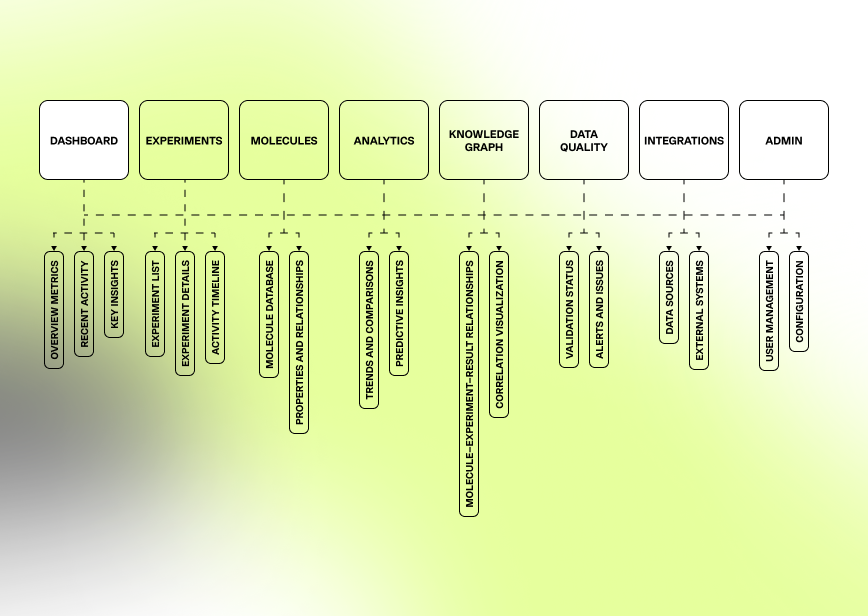
Structuring platform sections to provide clear access to experiments, molecules, analytics, knowledge graph insights, and data quality controls.
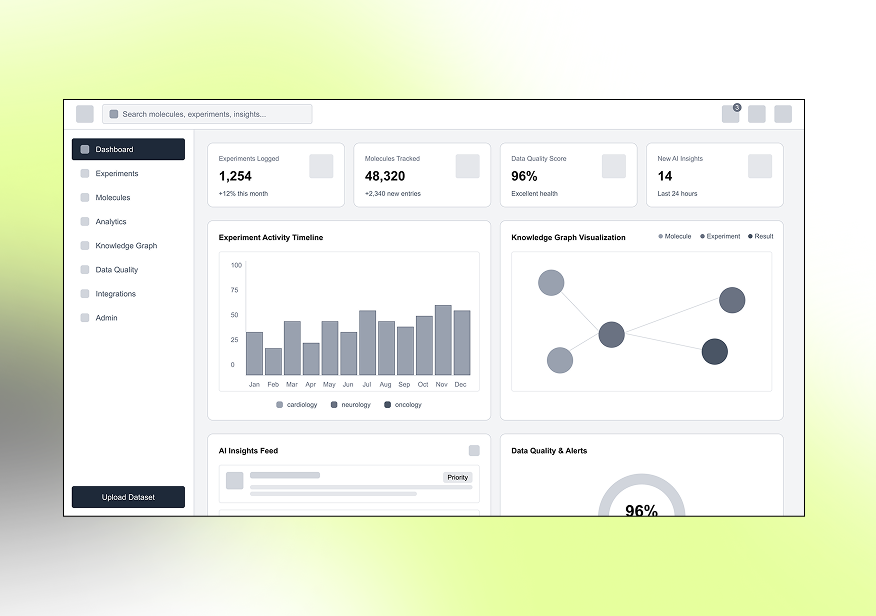
Designing low-fidelity layouts that define core research flows, data exploration paths, and interactions before visual refinement.

Creating an intuitive, analytics-driven interface that visualizes complex laboratory data, AI insights, and knowledge graph relationships in a clear, actionable way.

PYTHON
Python is used as the core language for data processing, NLP pipelines, and machine learning workflows. It enables efficient extraction, normalization, and analysis of unstructured pharmaceutical research data across R&D systems.
NLP (spaCy / Transformers)
NLP frameworks are used to extract entities, properties, and relationships from laboratory documents such as PDFs, spreadsheets, and text notes. This reduces manual processing and ensures consistent interpretation of experimental data.

KNOWLEDGE GRAPH (Neo4j)
Neo4j is used to model relationships between molecules, experiments, reaction conditions, and outcomes. The graph-based approach enables the discovery of hidden correlations and supports advanced analytical queries.

POSTGRESQL
PostgreSQL stores structured and validated experimental data, ensuring consistency, traceability, and reliable access across R&D workflows.
DOCKER
Docker is used to containerize data processing, NLP, and graph services. It ensures consistent environments across development, testing, and production.

KUBERNETES
Kubernetes orchestrates containerized services, managing deployment, scaling, and service availability. It enables the platform to handle growing data volumes and computational workloads reliably.

AI ASSISTANT & PREDICTIVE MODELS
Python-based machine learning models forecast experimental outcomes and surface data anomalies based on structured lab data. An LLM-powered assistant with RAG architecture enables natural-language access to historical research records, accelerating discovery and supporting real-time scientific decision-making.
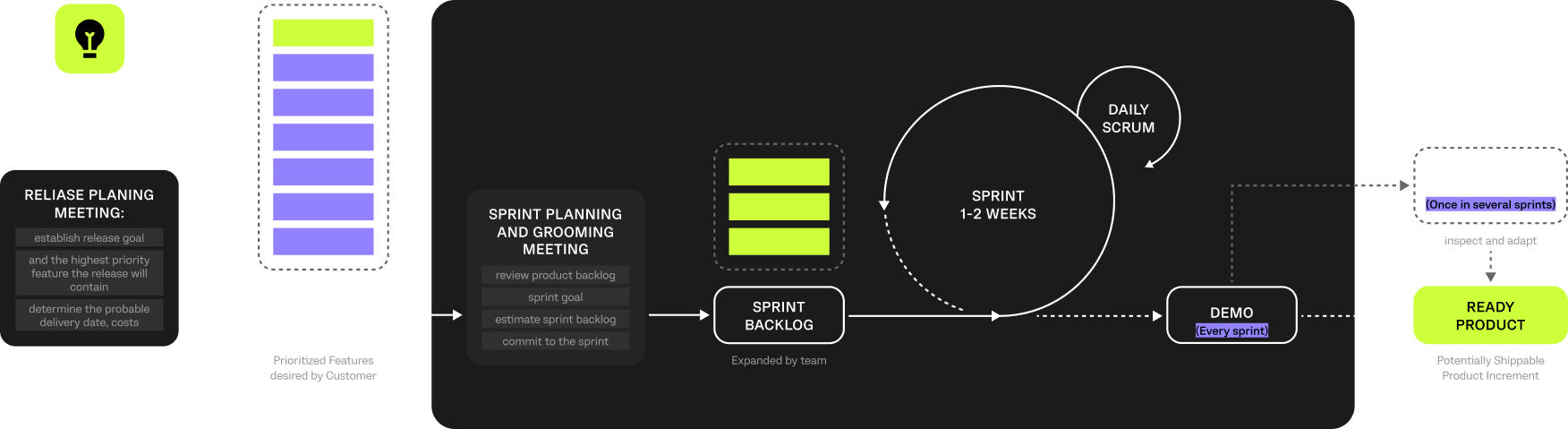
To deliver the platform efficiently and align with evolving R&D needs, a Scrum-based model was used. Work was structured in short iterations with ongoing prioritization, stakeholder reviews, and validation of data models and user flows. This ensured transparency, predictable progress, and adaptability to new research needs and data constraints.
Data is the key to more effective drug discovery, and the ability to integrate AI gives us a major advantage today. Computools helped us build a platform that unlocked access to all our accumulated research experience. Now our R&D works much faster: we can quickly test hypotheses, plan new trials, and make decisions based on complete data and analytics. The platform connects the past and the future, allowing us to see patterns that had previously remained hidden in our records.

Computools | 341 Raven Cir, Camden Wyoming, Delaware 19934, US





