THE AUTHOR:

The global EHR market is entering a rapid growth phase, creating direct pressure on how healthcare data platform development is approached and scaled.
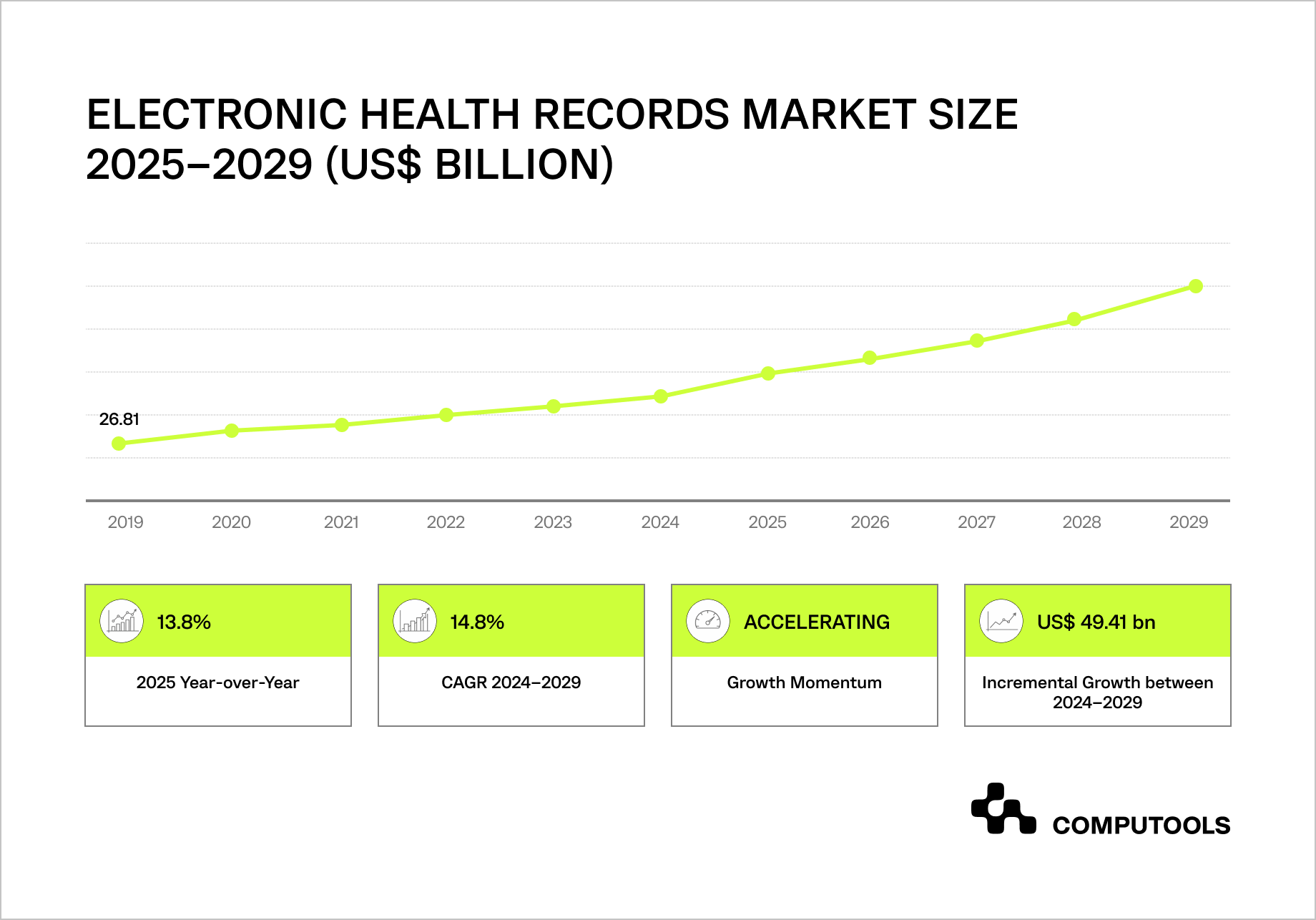
Between 2024 and 2029, the Electronic Health Records market is expected to grow by $49.4 billion at a 14.8% CAGR, with North America driving nearly 45% of total growth.
At the same time, more than $17.8 billion in EHR infrastructure still runs on on-premises deployments, storing vast volumes of sensitive patient data within systems that were never designed to support large-scale analytics, AI, or cross-system data reuse.
As healthcare organizations expand into analytics, population health, telemedicine, and AI, they face a growing set of structural risks: fragmented data spread across EHRs and downstream tools, inconsistent access control, duplicated PHI, and limited auditability across integrations.
Building secure health information systems has become a critical requirement, as security and governance gaps now directly limit scalability, slow innovation, and increase exposure when clinical and operational data moves beyond core EHR boundaries.
To show how to address these challenges, we’ll examine a real-world case of developing an advanced pharma R&D platform that transforms unstructured lab data into an insight-ready research environment.
How we built a secure health data platform without breaking existing healthcare workflows
We worked with a Switzerland-based pharmaceutical company that needed to operationalize more than ten years of laboratory and experimental data. Over time, this data accumulated across PDFs, spreadsheets, and text-based research notes, making it increasingly difficult for R&D teams to find, verify, and reuse previous results. The company wanted to move toward analytics and data-driven research without disrupting established workflows or rewriting existing processes.
As data volumes grew, researchers spent more time searching archives than working on new hypotheses. Experiments were often repeated simply because earlier results were hard to locate or lacked sufficient context. At the same time, expanding access to historical research data introduced governance and security concerns as more teams and tools became involved.
While MoleculeNetLab focuses on research data rather than EHR records, the architecture follows the same core principles: governed ingestion, semantic standardization, least-privilege access, and end-to-end auditability.
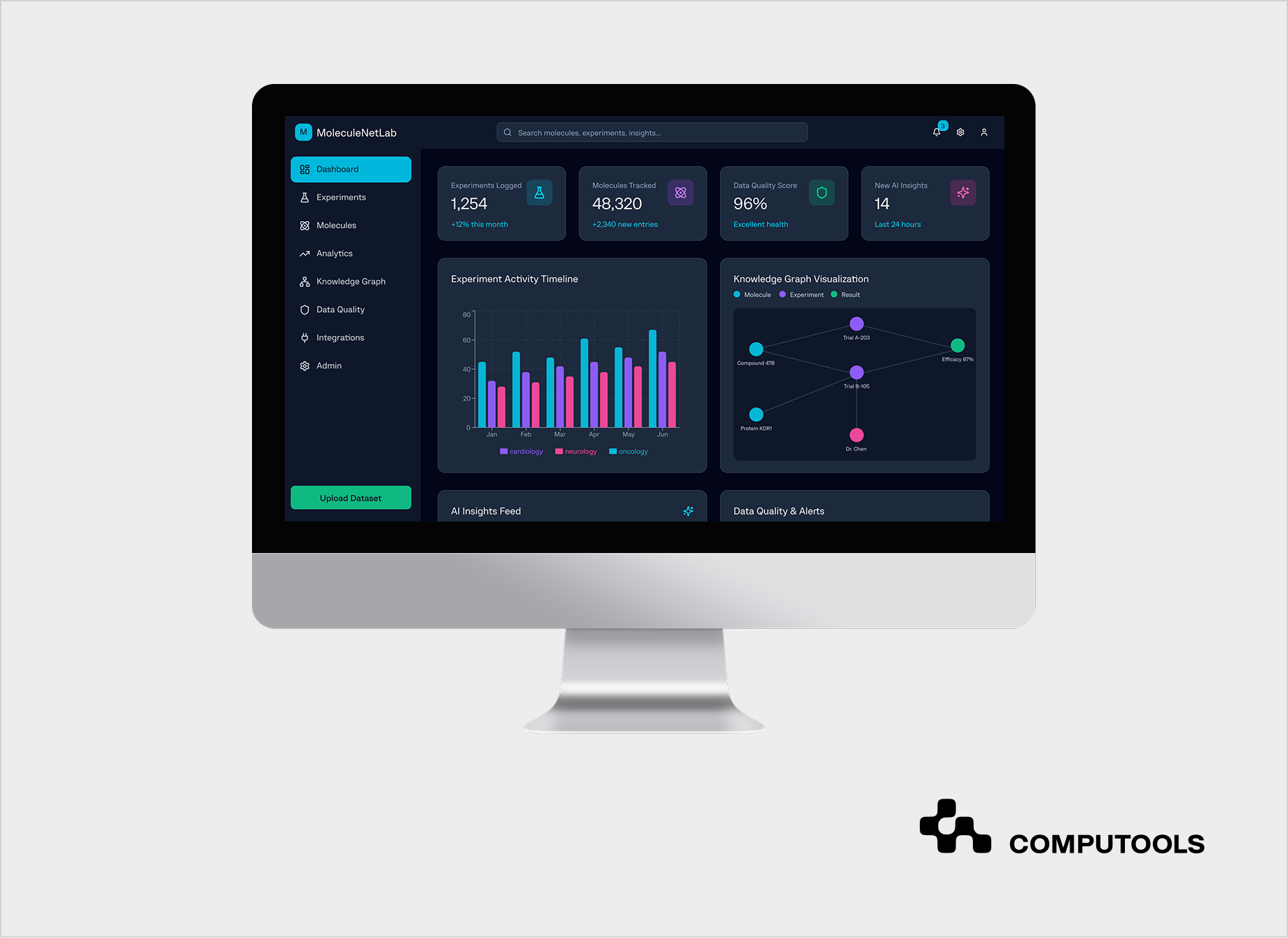
We designed MoleculeNetLab as a secure intelligence layer built on top of existing pharma R&D systems and research data sources. Using AI-based extraction and semantic modeling, unstructured documents were converted into structured datasets with consistent terminology and clear links between experiments, reaction conditions, and outcomes. Access control, auditability, and data lineage were built into the platform from the start, enabling safe reuse of historical data without changing how researchers work day-to-day.
This approach reduced duplicate experimentation and improved visibility across R&D initiatives. Scientists gained faster access to connected historical data and could validate new ideas using a complete experimental context rather than isolated records. Research decisions became more grounded, while existing workflows remained intact.
This delivery approach builds on our experience delivering hospital software development services, where security, auditability, and workflow continuity are non-negotiable.
It also reflects our broader expertise in web platform development for complex, data-intensive systems that must scale over time without introducing operational or compliance risk.
In the next section, we walk through our approach step by step and explain how to build a secure health data platform on top of EHR systems, drawing directly on this experience and similar healthcare projects.
How to build a secure health data platform on top of EHR systems
Step 1. Define clear boundaries between EHR systems and the data platform
The key step in building a secure data platform over EHR systems is setting a clear architectural boundary. EHRs are intended to document care, support workflows, facilitate billing, and ensure legal traceability. They prioritize reliability and compliance, not analytics, large-scale data reuse, or AI workloads. Using EHRs as a reporting or intelligence layer can lead to performance issues, fragile integrations, and security problems that do not scale.
A sustainable approach starts with separating concerns. The EHR remains the system of record, responsible for capturing and maintaining clinical truth. The data platform becomes a separate intelligence system, responsible for interpreting, aggregating, and reusing data across analytics, research, and downstream applications.
This separation is the foundation of sound health data platform architecture, because it defines where data is sourced, where it is transformed, and where it is safely consumed without interfering with day-to-day clinical operations.
In practical terms, this means designing the platform as an independent layer that reads from EHRs via governed interfaces, rather than embedding logic within core clinical systems. The platform maintains its own internal data models, governance rules, and audit trails, shielding analytical workloads from changes in EHR schemas or vendor-specific implementations. This enables organizations to evolve their reporting, AI, and population-level insights over time without turning every EHR upgrade into a high-risk event.
It is also critical to plan for change from the beginning. EHR vendors update APIs, clinical terminology evolves, and new data sources appear as care models expand. A well-designed platform absorbs this variability through versioned ingestion, standardized internal representations, and a semantic layer that maintains stability for downstream consumers. When this boundary is missing, every change upstream ripples through analytics, dashboards, and integrations—creating operational drag and security gaps.
We applied the same principle in the MoleculeNetLab project. Instead of modifying existing research systems or imposing new documentation practices, we treated historical records as immutable sources of truth and built the intelligence layer on top of them. This allowed analytics and AI capabilities to grow without disrupting established workflows, a pattern that directly translates to EHR-based environments.
Step 2. Build a governed integration layer instead of point-to-point connections
Once architectural boundaries are defined, the next critical step is how data actually moves from EHR systems into the platform. The most common mistake at this stage is relying on point-to-point integrations: custom APIs, direct database access, or tightly coupled connectors built for a single use case. While this approach may work short-term, it quickly becomes unmanageable as data volumes grow, new consumers appear, and compliance requirements tighten.
A secure platform requires a dedicated integration layer that acts as the single controlled entry point for EHR data. This layer enforces consistency, validation, and traceability before data flows downstream. In practice, an effective EHR data integration platform abstracts away vendor-specific APIs, data formats, and update cycles, replacing them with standardized ingestion patterns that the rest of the system can rely on.
Governance at this layer is essential. All datasets must be identifiable, versioned, and auditable upon entry, with schema validation, handling of partial data, and metadata capture. Treating integration as a governed capability enables scalable analytics and AI without reworking ingestion logic.
In real healthcare environments, interoperability is rarely clean. EHR systems expose data at different levels of granularity, apply inconsistent coding standards, and evolve independently over time. A strong integration layer absorbs this variability instead of pushing it downstream. It shields analytics teams, data scientists, and application developers from the operational realities of EHR change, reducing both delivery risk and security exposure.
This approach mirrors how we handled historical research data in MoleculeNetLab. Rather than connecting analytical tools directly to raw documents or source systems, we introduced a controlled ingestion layer that standardized and validated data before it became available for use.
That decision prevented fragmentation early on and allowed the platform to grow without multiplying integration points, a pattern that applies directly when working with multiple EHRs and clinical systems.
Step 3. Standardize clinical meaning before you scale analytics
After integration, teams often rush straight into dashboards or ML. That’s where platforms start quietly breaking: the data may be “centralized,” but it still doesn’t mean the same thing across sources. Different EHRs may represent the same clinical event differently, use different codes, units, timestamps, and encounter logic, and sometimes store critical context in free text.
If you don’t standardize meaning early, you end up with conflicting metrics, brittle transformations, and security controls that are hard to apply consistently because the platform cannot reliably classify what is actually sensitive.
This is why Step 3 focuses on building the semantic and data-quality foundation that transforms raw EHR outputs into trusted, reusable datasets. In practice, this looks like a canonical internal model for the platform (your “house format”), mapping rules from each source system into that model, and a set of data quality checks that catch common healthcare failure modes: duplicates, missing identifiers, mismatched units, and partial updates. Mature healthcare data management systems treat this layer as part of the product, rather than as invisible glue code owned by a single analyst.
Integration moves data; standardization makes it usable. Your platform should answer questions such as “What is an encounter?” or “How do we define a readmission window?” consistently across analytics, applications, and AI workloads. Without this, teams must rebuild logic, resulting in a loss of trust and control.
This step is also where you prevent future governance headaches. Once data is standardized and classified, you can apply consistent policies around retention, masking, and access scopes because datasets have a stable meaning and structure. Without this step, “least privilege” becomes guesswork: you can’t reliably restrict access to sensitive elements if you can’t reliably identify them.
In MoleculeNetLab, the turning point was not just extracting data from documents, but standardizing terminology and relationships so researchers could compare experiments across time and projects without manual interpretation. That same principle applies to EHR-based platforms: the value arises when different sources no longer behave as distinct languages, and the platform becomes a shared, trustworthy layer for analytics and decision-making.
Step 4. Design access control around the clinical context
After data is integrated and standardized, the next major failure point is access control. Many healthcare platforms rely on basic role-based models inherited from source systems, assuming that job titles neatly define who should see what. In reality, clinical and analytical access is highly contextual. The same user may need different levels of visibility depending on the task, dataset, time window, or whether access is human- or system-driven.
This is where robust healthcare data security solutions move beyond static roles and focus on context-aware, least-privilege access. A secure data platform should distinguish between operational access, analytical access, and automated service access, and enforce different rules for each. Analysts should not see raw identifiers by default. AI services should not inherit human permissions. Temporary access should not silently become permanent.
From an architectural perspective, this means decoupling access logic from source systems and enforcing it centrally at the platform layer. Policies should be applied consistently across datasets, queries, and downstream tools, regardless of the data’s origin. This reduces the risk of accidental exposure and prevents the gradual erosion of security controls as new use cases are added.
In practice, access models must also support change. Research initiatives evolve, care models shift, and regulatory interpretations tighten. A platform that hard-codes permissions into pipelines or dashboards becomes fragile very quickly. Instead, access rules should be declarative, auditable, and adjustable without reengineering the entire system.
On the MoleculeNetLab platform, multiple research teams accessed the same underlying data under different security contexts. Scientists exploring historical experiments did not automatically gain access to sensitive metadata or unrelated projects. Analytical workflows operated on governed representations rather than raw documents. This allowed the client to confidently expand platform usage, knowing that broader access did not increase risk.
Step 5. Make auditability and compliance part of the platform’s core
In healthcare, security that cannot be proven will eventually fail. Many platforms technically “log activity,” but those logs are fragmented, incomplete, or disconnected from real data usage. When audits, incidents, or regulatory reviews happen, teams are forced to reconstruct history manually, which is slow, risky, and often inconclusive. A secure platform must treat auditability as a first-class architectural concern, not as an operational add-on.
A true HIPAA compliant data platform embeds audit trails into every layer of data interaction. This includes ingestion events, transformations, access requests, query execution, and downstream data consumption. Each action should be traceable to a specific identity (human or system), a clear purpose, and a precise dataset version. The goal is not just to satisfy audits, but to establish continuous accountability across the data lifecycle.
From a design perspective, this requires tight coupling between metadata, governance, and execution. Audit logs should be immutable, centrally stored, and aligned with platform semantics rather than raw infrastructure events. It should be possible to answer questions such as Who accessed this dataset? Through which interface? Under which policy? And what transformations were applied before the data was used? Without this level of clarity, compliance becomes reactive and brittle.
This step also plays a critical role in scaling analytics and AI development. As more automated processes interact with healthcare data, organizations need the same level of visibility into machine access as they do for human users. Service accounts, APIs, and background jobs must be governed and audited with equal rigor; they quickly become blind spots in the security model.
In MoleculeNetLab, full data lineage was not only a compliance requirement but also a scientific one. Analytical results needed to be traceable back to the original experiments, inputs, and assumptions. That same discipline applies to EHR-based platforms: when insights inform clinical, operational, or research decisions, organizations must be able to demonstrate precisely how those insights were derived and which data were used.
Security and compliance directly affect time-to-market, audit risk, and long-term platform costs. How to Design HIPAA-Compliant AI Architecture for Healthcare Applications explains how embedding compliance at the architectural level reduces rework and regulatory exposure later.
Step 6. Aggregate clinical data in a governed, reusable layer
Once governance, access control, and auditability are established, the platform enables data aggregation and reuse across analytics, reporting, and AI. Many healthcare initiatives fail at this stage because aggregation is handled ad hoc—within dashboards, notebooks, or application logic—rather than as a core platform feature.
A secure approach centralizes aggregation within the platform. Rather than allowing every consumer to build its own joins, filters, and derived metrics, the platform exposes curated, pre-aggregated datasets that reflect agreed-upon clinical and operational definitions. An effective EHR data aggregation platform ensures that commonly used views, cohorts, timelines, utilization metrics, and longitudinal patient records are built once, governed centrally, and reused consistently.
This matters for both security and correctness. When aggregation logic is scattered, sensitive data is repeatedly reshaped and copied, increasing exposure and making audits harder. Centralized aggregation reduces duplication, limits unnecessary access to raw data, and ensures downstream tools operate on the minimum data required for their purpose. It also prevents the slow drift in which different teams begin reporting different “versions of the truth” from the same EHR sources.
From an architectural standpoint, aggregation should respect the layers established earlier. Raw data stays raw. Standardized datasets remain immutable. Aggregated views are versioned, documented, and explicitly approved for use cases such as analytics, population health, or research. This separation allows the platform to evolve safely: new aggregations can be introduced without rewriting ingestion or weakening security controls.
In MoleculeNetLab, aggregation was the point where historical data became genuinely useful. Once experiments and conditions were connected and standardized, the platform could surface higher-level views that researchers actually needed, rather than forcing them to reconstruct context manually. The same pattern applies to EHR-based platforms: value emerges when aggregation is deliberate, governed, and reusable, not improvised at the edge.
Step 7. Enable advanced clinical and analytical use cases without increasing risk
At this stage, many healthcare platforms make a critical mistake: once data is integrated, standardized, governed, and aggregated, they relax discipline and open broad access “so teams can innovate faster.” This is where risk quietly re-enters the system. Advanced analytics, clinical decision support, and AI place fundamentally different demands on data than reporting does, and treating them the same undermines both security and trust.
Proper clinical data platform development separates capability from exposure. The platform should enable complex use cases, predictive modeling, cohort analysis, longitudinal studies, and decision support without granting unrestricted access to underlying data. This usually means exposing controlled analytical interfaces, feature-level datasets, and purpose-built views rather than raw clinical records. Innovation happens on top of governed representations, not directly on source-level data.
From a design standpoint, this step focuses on controlling intelligence generation. Models should use curated inputs with clear provenance. Outputs must be explainable, traceable, and reviewable, especially in clinical or research decisions. If the platform cannot explain the data, assumptions, and policies behind results, it cannot be safely used in healthcare. Human and non-human access must be distinguished; AI and analytical tools should have limited, specific permissions, not the same as clinicians. Overlooking this leads to “invisible users” bypassing governance.
In MoleculeNetLab, advanced analytics became possible only after this separation was enforced. Predictive insights and exploratory analyses were based on structured, approved datasets rather than on raw documents or experimental notes. Researchers gained powerful tools without compromising data governance or workflow integrity. The same principle applies to EHR-based platforms: sophisticated use cases are safest when the platform dictates the rules of engagement rather than individual tools.
Clinical decision support only delivers value when regulatory boundaries are clearly defined. How to Build an AI Clinical Decision Support SystemWithout Violating Regulations shows how to balance clinical impact with compliance and accountability.
Step 8. Design the platform to evolve with healthcare workflows and regulations
A secure health data platform is never a finished product. Healthcare regulations evolve, EHR vendors change APIs and data models, new clinical programs emerge, and analytical expectations grow. Platforms designed solely for current requirements tend to accumulate technical debt quickly, forcing organizations to implement reactive fixes that weaken security and slow delivery.
The final step is therefore about building for evolution. This means treating the platform as a long-term capability rather than a one-off integration project. Governance rules, access policies, semantic models, and aggregation logic must all be adaptable without requiring core component rewriting or disrupting existing users. Versioning, backward compatibility, and controlled rollout of changes are essential for stability in healthcare environments.
From an organizational perspective, this is where engineering discipline matters as much as architecture. Healthcare platforms operate at the intersection of compliance, operations, and innovation, and maintaining this balance requires teams that understand how clinical reality, data governance, and software systems interact in practice.
Mature healthtech software development services focus on delivery, maintainability, audit readiness, and the ability to absorb regulatory and business change over time.
In MoleculeNetLab, this mindset allowed the platform to grow beyond its initial scope. New datasets, analytical use cases, and research initiatives could be added without revisiting earlier architectural decisions or weakening security controls. The same approach applies to EHR-based platforms: when evolution is built into the design, organizations can expand safely rather than repeatedly rebuild.
The success of a secure health data platform is measured by its long-term support, not just its launch, ensuring it meets evolving demands without disrupting workflows, eroding trust, or compromising compliance.
Define your health data platform architecture, governance model, and delivery roadmap—engage engineering experts to estimate cost, effort, and time to deployment.
Why healthcare data platform development creates long-term value beyond EHR features
Modern healthcare organizations reach a ceiling when they treat EHRs as the primary engine for growth. Core clinical functionality is necessary, but it does not scale innovation on its own.
Strategic value emerges when data is decoupled from individual systems and reused across analytics, research, automation, and patient-facing services. This is where healthcare data platform development shifts from a technical initiative to a long-term business capability.
1. Interoperability as a platform function.
Mature platforms enable sustainable EHR interoperability solutions by replacing fragile, point-to-point integrations with a unified integration layer. Instead of adapting every downstream use case to EHR-specific formats and constraints, the platform standardizes data access and semantics in a single layer, enabling new systems and services to connect without increasing complexity.
2. Analytics and insight built on shared definitions.
When clinical and operational data flows through a central platform, analytics cease to be one-off implementations. Metrics, cohorts, and longitudinal views are defined once and reused consistently, reducing reporting discrepancies and increasing trust in insights across teams.
3. Faster delivery of advanced capabilities without workflow disruption.
Features such as AI-assisted decision support, automation, or cross-channel patient engagement can evolve independently on top of the platform. This avoids repeated changes to core EHR workflows while still allowing organizations to respond quickly to new clinical, operational, or regulatory demands.
4. Lower long-term risk and cost of change.
A platform absorbs new data sources, updated standards, and evolving regulations without forcing widespread rewrites. Over time, this reduces technical debt and makes innovation predictable rather than disruptive.
The key difference is leverage. EHR-centric customization delivers incremental gains. Platform-centric design compounds value with every new dataset, integration, and use case, allowing healthcare organizations to innovate without sacrificing stability or compliance.
Common mistakes in healthcare data platform design
Even well-funded healthcare initiatives fail not because of a lack of technology, but because of flawed early architectural decisions. Teams often focus on speed or feature delivery while underestimating the extent to which healthcare constraints shape data platforms.
Below are the most common mistakes we see in real-world healthcare data platform development and why they quietly undermine scale, security, and long-term value.
• Treating the data platform as an extension of the EHR. One damaging assumption is that the EHR can serve as an analytics layer. This overloads systems, weakens customizations, and exposes security flaws not intended for secondary use. EHRs are designed for documentation and compliance, not analytics or AI. Pushing logic into the EHR raises operational risks with each new use case.
• Building integrations as one-off technical projects. Many teams see healthcare API integration with EHR as just a delivery task rather than a strategic capability. Using custom endpoints, direct database access, or tightly coupled connectors may quickly solve issues but cause long-term fragility. When EHR APIs or data structures change, integrations break, audits get harder, and downstream systems become more complex. Scaling platforms require standardized, governed integration, not improvised solutions.
• Starting analytics before meaning is aligned. Organizations often invest heavily in dashboards and machine learning before resolving semantic inconsistency. Different definitions of encounters, medications, or outcomes coexist quietly until trust erodes. At that point, teams argue over numbers rather than act on insights. Without early standardization, analytics multiply confusion rather than clarity, regardless of the quality of the tooling.
• Underestimating engineering discipline in regulated environments. Healthcare platforms cannot be treated like generic data products. Medical data platform engineering requires versioned models, lineage tracking, auditability, and controlled change management from day one. When these concerns are deferred, compliance becomes reactive, security gaps emerge, and innovation slows as teams work around accumulated debt instead of building forward.
• Assuming security can be “added later.” Security retrofitting is among the most costly mistakes in healthcare. Access control, auditability, and data governance must be designed into the platform’s core workflows. Once data is widely copied, transformed, and exposed without consistent controls, restoring trust and compliance requires major rework, often under regulatory pressure.
• Optimizing for launch instead of longevity. Many platforms are designed to satisfy current reporting or regulatory needs, with little consideration for how they will evolve. Healthcare systems change continuously: regulations shift, care models expand, and analytical expectations grow. Platforms that cannot absorb change gracefully force organizations into repeated rebuilds, each riskier than the last.
Strong healthcare platforms are characterized by restraint, clear boundaries, and architectural discipline. When healthcare data platforms are engineered to scale safely, evolve predictably, and respect existing workflows, they become a durable foundation for innovation.
Why organizations choose Computools to build healthcare data platforms
Computools is a global software development and consulting company with 250+ engineers and 400+ delivered projects across regulated and data-intensive industries.
We operate under ISO 9001 and ISO 27001 standards and build solutions compliant with GDPR and HIPAA, which is critical for healthcare platforms where data security, auditability, and reliability are non-negotiable. Our teams are trusted by global enterprises such as Visa, Epson, and IBM, and we are official partners of Microsoft and AWS.
Our healthcare work is grounded in data engineering services designed for complex, regulated environments. We focus on building secure ingestion layers, governed data models, semantic consistency, and audit-ready architectures that can evolve without disrupting existing systems. This engineering-first approach ensures that healthcare data platforms remain stable as data volumes grow, regulations change, and new analytical use cases emerge.
On top of this foundation, we apply data science services tightly coupled to governance rather than isolated experimentation. Predictive models, analytics, and decision-support workflows are built on standardized, traceable datasets, enabling organizations to scale insight generation without compromising security or trust. This is especially important in healthcare contexts, where explainability and lineage matter as much as accuracy.
Our delivery record demonstrates measurable impact across data-intensive and regulated domains. In previous projects, we enabled up to 74% faster equipment tracking through RFID solutions, supported analytics platforms that drove 46% user growth, and delivered AI systems that improved operational productivity by 15% or more.
In healthcare and research-focused initiatives, the same outcome-driven engineering approach translates into healthcare analytics platform development where insights are reliable, auditable, and compliant by design.
What ultimately differentiates us is how we work. We do not treat healthcare data platforms as one-off implementations. We design them as long-term capabilities engineered to scale, adapt, and deliver ROI over time, so organizations can innovate confidently without accumulating technical or regulatory risk.
If you’re planning or reworking a healthcare data platform on top of existing EHR systems, we’re open to a technical conversation at info@computools.com.
Conclusion
Building a secure health data platform on top of EHR systems is an architectural choice, not a tooling exercise. When EHRs remain systems of record and data, analytics, and integrations are handled at the platform level, organizations gain control, scalability, and predictability instead of growing complexity.
This approach reduces risk, simplifies compliance, and makes analytics and innovation sustainable over time. In practice, it is the only way to build a healthcare IT infrastructure that can evolve without breaking clinical workflows or trust.
Automation in clinical documentation impacts both operational efficiency and data quality. How to Build an AI Clinical Documentation and Charting System for Hospitals outlines how to introduce AI-driven charting without disrupting workflows or increasing compliance risk.
Computools
Software Solutions
Computools is an IT consulting and software development company that delivers innovative solutions to help businesses unlock tomorrow.










“Computools was selected through an RFP process. They were shortlisted and selected from between 5 other suppliers. Computools has worked thoroughly and timely to solve all security issues and launch as agreed. Their expertise is impressive.”